The question “what is the natural log of infinity” might initially sound like a philosophical musing or a riddle, but within the realm of technology, it elegantly points towards fundamental concepts that underpin many of the advanced systems we interact with daily. While infinity itself isn’t a number in the conventional sense, the natural logarithm, denoted as “ln,” is a crucial mathematical function with profound implications in computing, data analysis, and algorithmic efficiency. Understanding how the natural logarithm behaves as its input approaches infinity is not just an academic exercise; it’s essential for comprehending the scaling capabilities of software, the optimization of complex algorithms, and the theoretical limits of computational processes. This article will delve into the mathematical underpinnings of the natural logarithm and infinity, and then explore their practical significance within the technology sector.

The Mathematical Foundation: Understanding ln(x) and Infinity
To grasp the concept of ln(∞), we first need to establish a clear understanding of the natural logarithm and the nature of infinity itself. These are not concepts confined to theoretical mathematics; they have direct bearing on how we design, build, and analyze technological systems.
The Natural Logarithm: A Function of Growth and Scale
The natural logarithm, ln(x), is the inverse of the exponential function e^x, where ‘e’ is Euler’s number, an irrational and transcendental constant approximately equal to 2.71828. In essence, ln(x) answers the question: “To what power must ‘e’ be raised to equal x?” For example, ln(e) = 1, ln(e^2) = 2, and so on.
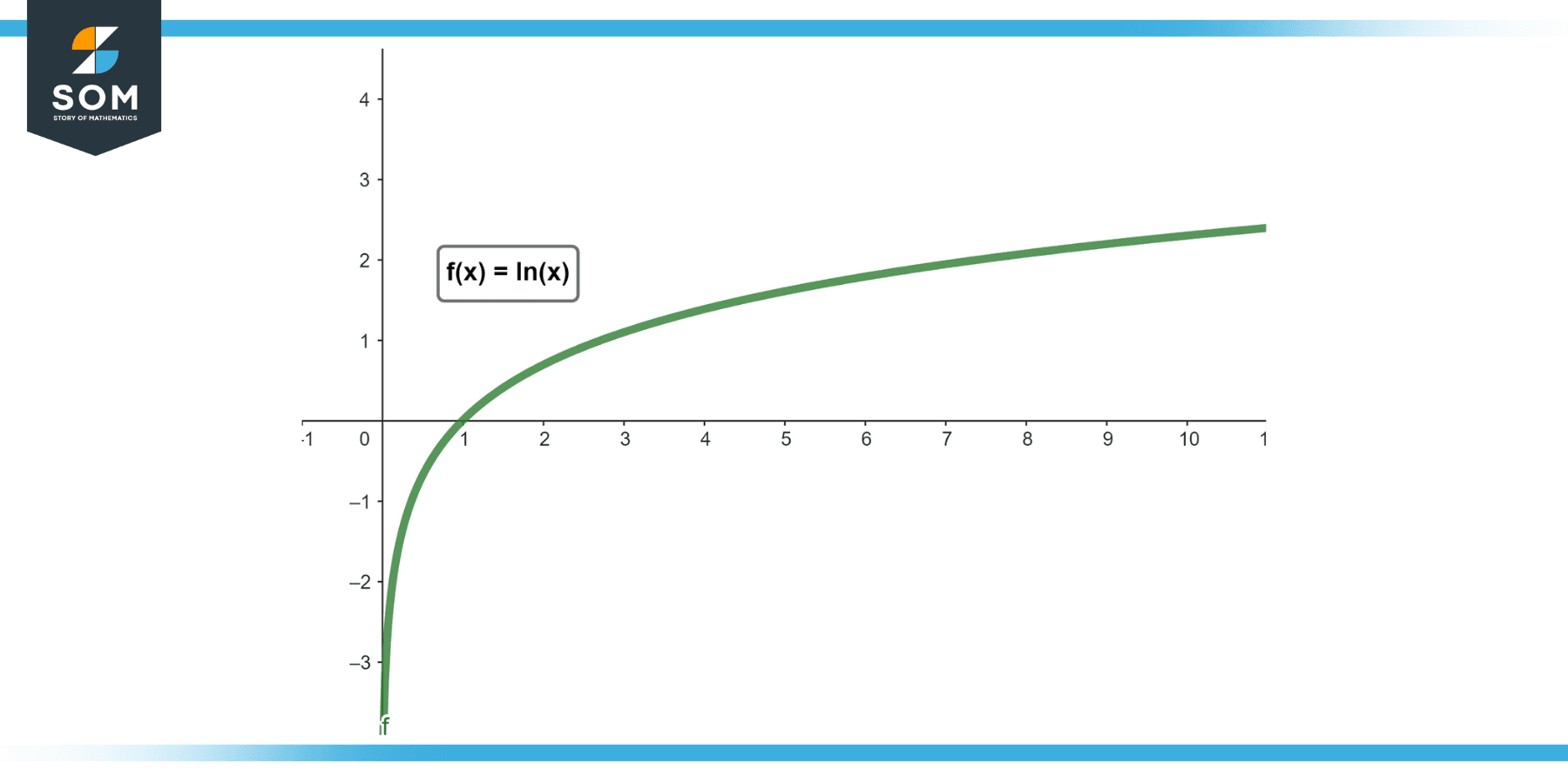
The natural logarithm is a slowly growing function. This is a critical characteristic. As the input value ‘x’ increases, the output of ln(x) increases, but at a progressively decelerating rate. Consider the values:
- ln(1) = 0
- ln(10) ≈ 2.30
- ln(100) ≈ 4.61
- ln(1,000) ≈ 6.91
- ln(1,000,000) ≈ 13.82
Even when the input increases by a factor of a thousand, the output only doubles. This characteristic of logarithmic growth is fundamental to its utility in technology.
Infinity: A Concept, Not a Number
Infinity (∞) is not a real number. It represents a concept of unboundedness, something without end or limit. In mathematics, we often deal with limits, which describe the behavior of a function as its input approaches a certain value, including infinity. When we discuss “the natural log of infinity,” we are, more precisely, examining the limit of ln(x) as x approaches infinity.
Mathematically, this is expressed as:
$$ lim_{x to infty} ln(x) $$
This notation asks: “What value does ln(x) get closer and closer to as x gets larger and larger without bound?”
The Limit of ln(x) as x Approaches Infinity
Since the natural logarithm is a slowly growing function, as its input ‘x’ grows infinitely large, the output of ln(x) also grows infinitely large, albeit slowly. There is no upper bound. Therefore, the limit of ln(x) as x approaches infinity is infinity.
$$ lim_{x to infty} ln(x) = infty $$
This mathematical truth is the bedrock upon which many technological applications are built. It tells us that while the growth is slow, it is still unbounded. This distinction between slow growth and bounded growth is crucial when assessing the scalability and efficiency of technological solutions.
Practical Implications in Technology: Scaling and Efficiency
The understanding that ln(∞) = ∞, coupled with the slow-growth nature of the natural logarithm, has profound practical implications in the technology sector, particularly in areas like algorithm design, data structures, and performance analysis.
Algorithm Complexity: The Power of Logarithmic Time
One of the most direct applications of logarithmic functions in technology lies in the analysis of algorithm complexity. When we describe the time complexity of an algorithm, we often use Big O notation, which provides an upper bound on the growth rate of the execution time or space requirements as the input size increases.
Algorithms with O(log n) time complexity are highly efficient. This means that as the input size ‘n’ doubles, the time required to execute the algorithm increases by only a constant amount. This is in stark contrast to algorithms with O(n) or O(n^2) complexity, where the execution time grows linearly or quadratically with the input size.
Consider these examples:
- Binary Search: This classic search algorithm finds the position of a target value within a sorted array. In each step, it eliminates half of the remaining search space. If you have an array of 1 million elements, binary search will take approximately log₂(1,000,000) ≈ 20 steps. If you double the array size to 2 million elements, it will only take about 21 steps. This is a perfect illustration of logarithmic efficiency. The “log” here is often base 2, but the fundamental principle of slow, unbounded growth (as the input approaches infinity) remains.
- Tree Traversal: Operations on balanced binary search trees (like AVL trees or Red-Black trees) often exhibit O(log n) complexity for operations like insertion, deletion, and search. As the number of nodes (n) in the tree grows, the depth of the tree (and thus the number of operations) grows logarithmically.
- Heap Operations: Operations on heaps, a data structure commonly used for priority queues, also typically have O(log n) complexity.
The fact that ln(∞) = ∞ is significant because it confirms that these O(log n) algorithms, while incredibly efficient for practical input sizes, will continue to scale. They won’t hit a performance ceiling that leads to unacceptable execution times even as data volumes grow astronomically. This makes them indispensable for handling massive datasets and complex computations in modern software.
Data Structures and Databases: Managing Information at Scale
The principles of logarithmic growth are fundamental to the design and performance of many data structures and databases that need to manage vast amounts of information efficiently.
- Balanced Trees: As mentioned, balanced binary search trees are critical for implementing efficient databases and file systems. Their O(log n) performance ensures that queries and data manipulation remain reasonably fast even as the database grows to terabytes or petabytes.
- B-Trees and B+ Trees: These are variations of binary trees optimized for disk-based storage, commonly used in relational databases (like PostgreSQL, MySQL) and file systems (like NTFS, HFS+). They are designed to minimize disk I/O operations by having a high branching factor, but the fundamental principle of logarithmic depth (and thus logarithmic access time) to locate data remains, making them scalable for enormous datasets.
- Hash Tables (with good distribution): While average-case operations on hash tables are often O(1), in the worst-case scenario (many collisions), performance can degrade. However, well-designed hash functions and collision resolution strategies aim to keep the average performance close to constant time, and their underlying principles are often discussed in relation to logarithmic growth for certain theoretical analyses.
The ability of these data structures to handle an ever-increasing number of records without a proportional explosion in access times is directly related to the slow, unbounded nature of logarithmic growth. The “natural log of infinity” being infinity means that even with unlimited data, these structures will continue to function, albeit taking longer, but in a predictable and manageable way.
Network Routing and Information Retrieval
Logarithmic complexity also plays a role in algorithms used for network routing and efficient information retrieval. For instance, some routing algorithms might use tree-like structures to determine the most efficient path for data packets, where the number of hops or lookups grows logarithmically with the size of the network. Similarly, certain indexing techniques in search engines or large-scale information systems rely on structures that allow for fast lookups, often with logarithmic time complexity.
The “Unboundedness” Aspect: When Logarithmic Isn’t Enough
While O(log n) complexity is highly desirable, the fact that ln(∞) = ∞ is also a reminder that even the most efficient algorithms will eventually become too slow if the input size grows beyond a certain practical limit, or if the constants hidden within the Big O notation become significant.
Constant Factors and Practical Limits
Big O notation abstracts away constant factors and lower-order terms. An algorithm with O(log n) complexity might be significantly faster than an algorithm with O(n) complexity for most practical input sizes. However, if the constant factor multiplying the log(n) term is extremely large, it could theoretically be slower than an algorithm with a smaller constant factor multiplying ‘n’ for smaller values of ‘n’.
For example, if Algorithm A has a time complexity of $1000 log_2 n$ and Algorithm B has a time complexity of $10n$, for small values of n, Algorithm B might outperform Algorithm A. However, as ‘n’ grows, the logarithmic growth of Algorithm A will eventually make it superior.
The practical limit is often dictated by hardware capabilities, memory constraints, and acceptable response times. Even if an algorithm is theoretically unbounded in a positive way, real-world systems have finite resources.
Beyond Logarithmic: The Need for Different Approaches
In scenarios involving truly massive datasets or computationally intensive problems where even logarithmic growth is insufficient, developers must explore alternative algorithmic paradigms or distributed computing solutions.
- Linearithmic Growth (O(n log n)): Algorithms like Merge Sort and Quick Sort have a time complexity of O(n log n). This is still considered very efficient for large datasets and is a common performance benchmark for sorting algorithms. It represents a slightly faster growth rate than pure logarithmic but significantly better than quadratic.
- Distributed Computing: For problems that are too large or complex for a single machine, distributed computing frameworks (like Apache Spark, Hadoop) break down tasks into smaller pieces that can be processed in parallel across multiple machines. This approach addresses the “unboundedness” not by making a single algorithm infinitely fast, but by distributing the workload infinitely (in theory) across an ever-increasing number of computational resources.
- Approximation Algorithms: In some cases, finding an exact solution might be computationally intractable (e.g., NP-hard problems). In such scenarios, approximation algorithms are used to find a solution that is close to optimal, often with provable bounds on how far it deviates from the true optimum. The complexity of these algorithms can vary, but they are designed to be tractable.
The “natural log of infinity” being infinity implies that we can keep pushing the boundaries of what’s possible with efficient algorithms. However, it also highlights that for problems that explode in complexity, we need to rethink our fundamental approach, often by leveraging parallel processing or accepting a degree of approximation.
Conclusion: The Enduring Relevance of ln(∞) in Technological Advancement
The question “what is the natural log of infinity” might initially seem abstract, but its answer – infinity – underpins much of the progress and innovation within the technology sector. The natural logarithm’s characteristic of slow, unbounded growth makes it a cornerstone of efficient algorithm design, enabling us to process and manage ever-increasing volumes of data.
From the efficient search capabilities of binary search to the scalable performance of databases built on balanced trees, the logarithmic function is silently at work, making complex computations feasible and large-scale systems manageable. Understanding this relationship allows technologists to:
- Design and select algorithms that can gracefully handle growing datasets.
- Predict and analyze performance of software systems as they scale.
- Identify potential bottlenecks when even logarithmic growth becomes a limiting factor.
- Develop innovative solutions that leverage parallel processing or approximation techniques for problems that exceed the limits of single-threaded logarithmic performance.
In essence, the natural log of infinity is a testament to the power of mathematics in shaping the digital world. It’s a concept that assures us that while challenges of scale are real, the tools and principles derived from understanding mathematical limits provide a robust foundation for continued technological advancement. The journey from a simple mathematical inquiry to its profound impact on the sophisticated systems we rely on daily is a powerful illustration of how theoretical knowledge fuels practical innovation.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.