In the intricate world of technology, innovation, and digital advancement, understanding the fundamental building blocks of experimentation is paramount. Whether you’re developing a new AI algorithm, optimizing a software application, or testing the efficacy of a novel gadget, the concept of a “variable” is central to any rigorous investigative process. This article delves into the nature and significance of variables within the context of technological experimentation, offering a clear understanding for developers, researchers, and enthusiasts alike.
The Cornerstone of Technological Experimentation: Defining Variables
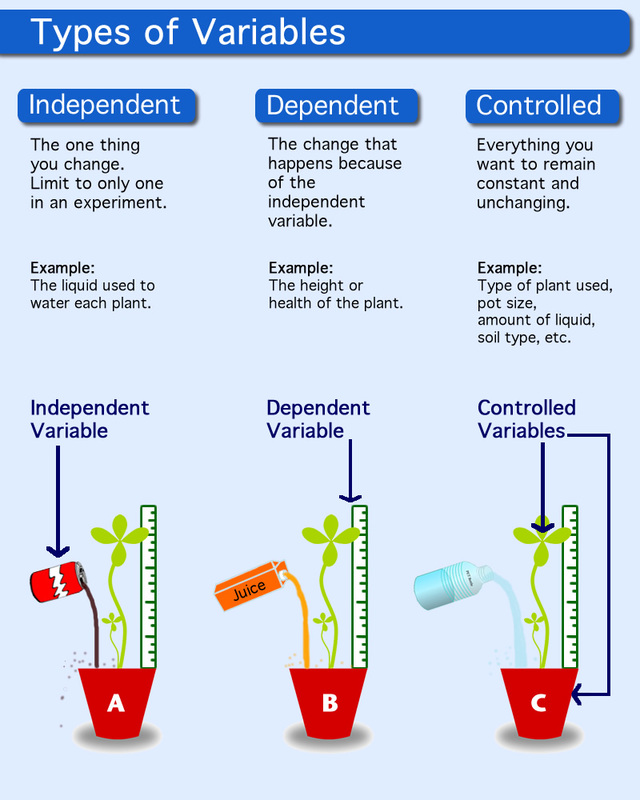
At its core, a variable in a technological experiment is any factor, characteristic, or element that can change or be changed. It’s the “what if” that drives innovation, the element we manipulate or observe to understand cause and effect in the digital realm. Without variables, experiments would be static observations, incapable of revealing the dynamic relationships that underpin technological progress. In essence, variables are the levers we pull, the dials we turn, and the metrics we monitor to gain actionable insights.

Independent Variables: The Agents of Change
The independent variable, often referred to as the “manipulated variable” or “input variable,” is the factor that the experimenter deliberately changes or controls. In technological contexts, this could be anything from altering a parameter in an algorithm, modifying a user interface element, introducing a new feature to an app, or adjusting the clock speed of a processor. The independent variable is the presumed cause in a cause-and-effect relationship. We change it to see what effect it has on something else.
For instance, in testing the performance of a new machine learning model, the learning rate (a parameter controlling how much the model adjusts its weights with respect to the loss gradient) would be an independent variable. Researchers might test the model with learning rates of 0.001, 0.01, and 0.1 to observe how this change impacts the model’s accuracy and convergence speed. Similarly, in developing a mobile application, the placement of a “buy now” button (e.g., top of the page versus bottom) could be an independent variable manipulated to see its effect on conversion rates.
Dependent Variables: The Outcomes of Interest
The dependent variable, also known as the “measured variable” or “output variable,” is what we measure or observe to see if it is affected by the changes made to the independent variable. It’s the presumed effect. In technology, dependent variables can encompass a wide array of metrics, from performance indicators and user engagement statistics to error rates and system resource utilization.
Continuing the machine learning example, the accuracy of the model’s predictions, the time it takes for the model to train, or the amount of memory it consumes would be dependent variables. We measure these to determine if the different learning rates (independent variables) have a significant impact. In the app development scenario, the conversion rate (the percentage of users who click the “buy now” button and complete a purchase) would be the dependent variable. Other dependent variables in software development could include response times, uptime percentages, user satisfaction scores, or the number of reported bugs.
Types of Variables in Tech Experimentation
Beyond the fundamental distinction between independent and dependent variables, other classifications are crucial for designing robust and reliable technological experiments. Understanding these distinctions helps researchers isolate the effects of interest and control for extraneous influences.
Controlled Variables: Ensuring a Fair Test
Controlled variables are factors that are kept constant throughout an experiment. Their purpose is to prevent them from influencing the dependent variable, thereby ensuring that any observed changes are indeed due to the manipulation of the independent variable. In technology, maintaining consistent environments is paramount for reproducible results.
Consider an experiment testing the battery life of different smartphone models. The screen brightness, Wi-Fi connection status, background app activity, and the specific test scenario (e.g., continuous video playback) would all be controlled variables. If these were allowed to vary, it would be impossible to attribute differences in battery life solely to the inherent capabilities of each phone. In software performance testing, controlled variables might include the operating system version, hardware specifications of the testing machines, network latency, and the size and complexity of the dataset being processed.
Confounding Variables: The Unseen Influences
Confounding variables, also known as lurking variables or extraneous variables, are factors that are not intentionally manipulated but can influence both the independent and dependent variables, leading to spurious correlations or obscuring true relationships. Identifying and mitigating confounding variables is a critical aspect of experimental design, particularly in complex technological systems where numerous factors interact.
In an A/B test on a website, for example, the time of day a user visits could be a confounding variable if one version of the page is shown predominantly during peak hours and another during off-peak hours. This might lead to apparent differences in engagement that are not due to the page design itself but to user behavior patterns at different times. Another example could be in testing the performance of a new web server. If the testing period coincides with a major software update on the network infrastructure, this update could be a confounding variable affecting the perceived performance of the web server. Researchers often use statistical techniques or careful experimental design to account for or eliminate the influence of confounding variables.
The Importance of Variables in Software Development and AI
The meticulous handling of variables is not just an academic exercise; it’s the engine that drives progress in fields like software development and artificial intelligence. These domains are inherently experimental, constantly seeking to improve performance, enhance user experience, and unlock new capabilities.
Optimizing Algorithms and Performance
In the realm of AI and machine learning, variables are central to the iterative process of algorithm development. Hyperparameters – settings that are not learned from data but are set before training begins – are a prime example of independent variables. The choice of activation function, the number of layers in a neural network, the regularization strength, and the optimizer used are all hyperparameters that can be varied to tune the model’s performance. The dependent variables here are typically measures of the model’s predictive accuracy, generalization ability, computational efficiency, and robustness.
For software performance optimization, variables play a crucial role in identifying bottlenecks and areas for improvement. Developers might experiment with different data structures, caching strategies, or asynchronous processing techniques (independent variables) to see their impact on application response times, memory usage, or throughput (dependent variables). Understanding how these elements interact allows for the creation of more efficient and scalable software solutions.
Enhancing User Experience (UX) and Interface Design
User experience is a paramount concern in the design of any digital product, from mobile apps to complex enterprise software. Variables are instrumental in understanding how users interact with technology and what design choices lead to greater satisfaction and efficacy.
In A/B testing, which is a common method for optimizing web and app interfaces, variations in design elements are treated as independent variables. This could include the color of a button, the text on a call-to-action, the layout of a page, or the introduction of a new feature. The dependent variables are user behavior metrics such as click-through rates, conversion rates, time spent on page, bounce rates, and task completion success. By systematically manipulating these design variables and observing their impact on user behavior, designers can create interfaces that are more intuitive, engaging, and ultimately, more successful.
Designing Experiments with Variables in Mind
The success of any technological experiment hinges on a well-defined experimental design that thoughtfully incorporates variables. This involves careful planning, clear objectives, and a systematic approach to manipulation and measurement.
Formulating Hypotheses
A hypothesis is a testable prediction about the relationship between variables. In technology, a hypothesis might state that “Increasing the cache size (independent variable) will decrease the average page load time (dependent variable) by at least 15%.” A well-formulated hypothesis provides direction for the experiment and a clear benchmark against which to measure results. It helps in identifying the key variables that need to be manipulated and measured.

Methodologies for Variable Manipulation and Measurement
Various methodologies are employed to manipulate independent variables and measure dependent variables in technology. For software and AI, this often involves:
- Parameter Tuning: Adjusting numerical values of hyperparameters in machine learning models.
- Configuration Changes: Modifying settings in software systems, databases, or network devices.
- A/B Testing: Presenting different versions of an interface or feature to different user groups.
- Controlled Benchmarking: Running standardized tests on hardware or software under specific, controlled conditions.
- Simulations: Creating virtual environments to test the behavior of systems under various variable inputs.
Measurement of dependent variables can involve:
- Performance Monitoring Tools: Software that tracks system metrics like CPU usage, memory consumption, and network traffic.
- Analytics Platforms: Tools that gather user behavior data on websites and apps.
- Logging Systems: Recording events and errors within software applications.
- User Surveys and Feedback Forms: Collecting qualitative and quantitative data on user satisfaction.
- Statistical Analysis: Applying mathematical methods to interpret the collected data and determine the significance of observed changes in dependent variables.
By understanding and effectively utilizing variables, technologists can move beyond guesswork and intuition, embarking on a path of rigorous, data-driven experimentation that fuels innovation and shapes the future of technology. The ability to define, control, and analyze variables is a fundamental skill for anyone involved in building, testing, or improving the digital world around us.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.