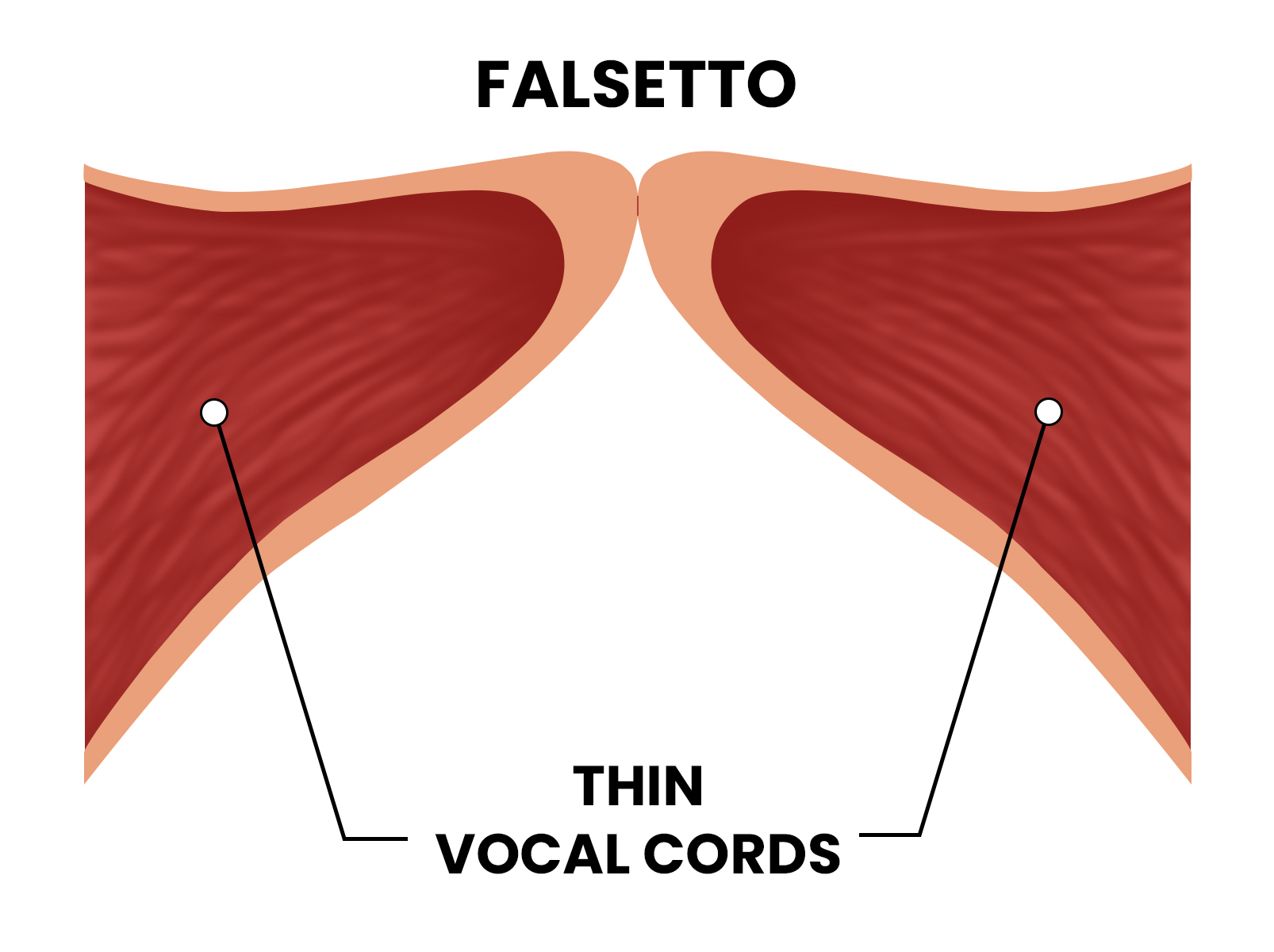
In the traditional sense, falsetto is a vocal register that allows singers to reach notes beyond their normal range by vibrating only the ligamentous edges of the vocal cords. However, in the rapidly advancing landscape of audio technology, the question “what is falsetto voice” has taken on a profoundly different meaning. We are no longer simply discussing human anatomy; we are discussing the digital reconstruction of timbre, the algorithmic manipulation of pitch, and the rise of artificial intelligence in replicating one of the most complex nuances of human expression.

For technologists, software developers, and audio engineers, falsetto represents a unique challenge in Digital Signal Processing (DSP). It is characterized by a high fundamental frequency and a distinct lack of harmonic richness compared to the “chest voice.” This article explores the technical architecture of falsetto within the realms of AI tools, synthesis software, and the future of digital audio.
The Mechanics of Digital Voice: Understanding Falsetto in DSP
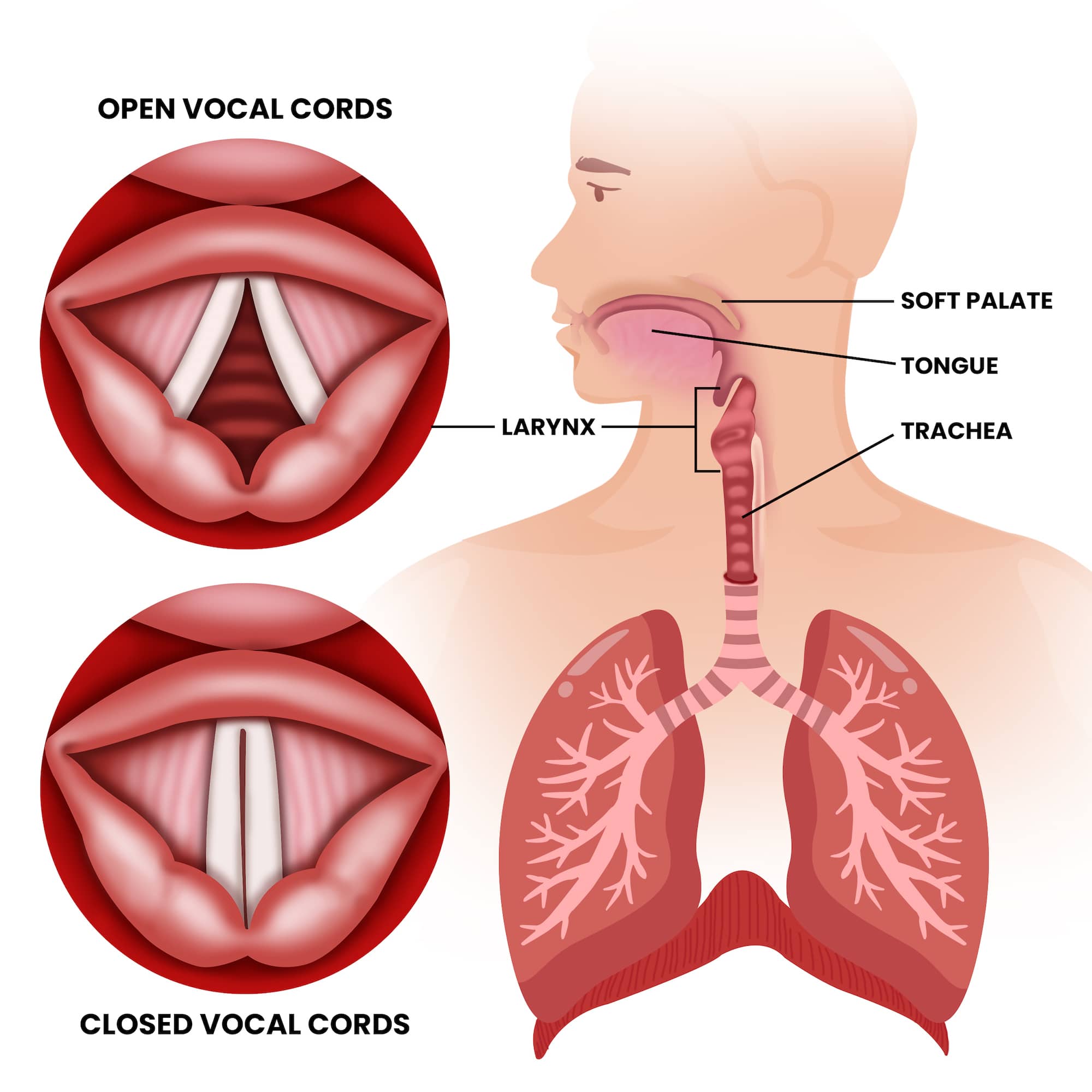
At the core of modern audio technology lies Digital Signal Processing (DSP). To understand falsetto from a tech perspective, we must look at how sound waves are captured, analyzed, and resynthesized. Unlike the robust, harmonic-heavy “modal” voice, falsetto produces a wave pattern that is closer to a sine wave but with specific “breathiness” or noise components that are difficult to model.
Frequency Analysis and Pitch Tracking
The first step in any voice-related technology—whether it is a digital tuner or an AI-driven voice changer—is pitch detection. Falsetto operates in a high-frequency spectrum, often ranging from 250 Hz to over 1000 Hz. For software to accurately identify a falsetto note, it employs Fast Fourier Transform (FFT) algorithms to convert time-domain signals into frequency-domain data.
The challenge for tech tools is distinguishing falsetto from “head voice” or “whistle register.” Advanced pitch-tracking software uses autocorrelation and cepstral analysis to look at the spacing of harmonics. Because falsetto has thinner harmonic peaks, the software must be tuned to high sensitivity to avoid “octave jumping,” a common glitch where the software incorrectly identifies the pitch as being an octave lower than it actually is.
Harmonic Reconstruction in Virtual Instruments
Virtual Studio Technology (VST) instruments aim to recreate the human voice using samples or oscillators. When a developer builds a “Virtual Vocalist,” they must account for the physical transition into falsetto. This is often handled through “multi-sampling,” where dozens of recordings of a human singer are mapped to different velocity layers.
However, the cutting edge of this tech is “Physical Modeling Synthesis.” Instead of playing back a recording, the software simulates the physics of the human throat. To replicate falsetto, the algorithm must decrease the simulated “mass” of the vocal folds and increase the “tension,” while adding a stochastic (randomized) noise element to simulate the air escaping through the glottis. This marriage of physics and code is what allows modern gadgets to produce life-like vocal performances.
AI and the Evolution of Vocal Synthesis
The most significant leap in understanding “what is falsetto voice” in a tech context comes from Generative AI. We have moved past simple synthesis into the era of Neural Networks, where machines learn the “soul” of a voice through massive datasets.
Generative AI and Neural Networks in Vocal Replication
Modern AI voice models, such as those utilizing RVC (Retrieval-based Voice Conversion) or So-VITS-SVC, treat falsetto as a specific set of data points within a latent space. When an AI is trained on a singer, it categorizes different vocal textures. The falsetto register is often the hardest for AI to master because it requires the model to understand the relationship between “breathiness” and “pitch accuracy.”
Neural networks use “diffusers” to clean up the audio. In the context of falsetto, the AI must predict where the harmonics should lie even when the input signal is weak. This has led to the rise of “AI Covers,” where technology allows a gravelly-voiced singer’s input to be transformed into a soaring, crystalline falsetto in the style of a completely different artist.
Real-time Pitch Shifting and Formant Preservation
One of the greatest hurdles in vocal tech is the “Mickey Mouse effect.” When you shift a voice up to simulate a falsetto range using basic algorithms, the “formants” (the resonant frequencies of the vocal tract) shift as well, making the voice sound artificial and tiny.
Advanced AI tools and high-end plugins now use Formant Preservation technology. This tech uncouples the pitch from the resonance. By shifting the fundamental frequency into the falsetto range while keeping the formants stable, the software creates a realistic “high voice” that sounds like a human being rather than a digital artifact. This is critical for real-time applications like Vtubing, digital security (voice masking), and live performance enhancement.
The Software Ecosystem for Modern Vocal Production
The professional audio industry relies on a suite of sophisticated tools to manipulate the falsetto register. These tools have become essential for everything from pop music production to voice-over work in AAA video games.
VSTs and Plugins: Simulating the Human Falsetto
Synthesizers like Yamaha’s Vocaloid or Dreamtonics’ Synthesizer V have revolutionized how we perceive falsetto. Synthesizer V, in particular, uses a “neural engine” that can take a MIDI melody and automatically apply falsetto transitions where a human singer naturally would. This is not just a playback of a note; it is a software-driven decision based on the linguistic context of the lyrics and the musical context of the melody.
For engineers, the “falsetto” is often the focal point of a mix. Tech tools like spectral editors (e.g., iZotope RX) allow users to see the “breath” of a falsetto note as a cloud of energy on a spectrogram. Engineers can then use “Dynamic EQ” to control the piercing frequencies that often accompany high-register singing, ensuring the digital output is pleasant to the ear.
Auto-Tune and Melodyne: The Science of Correction
No discussion of vocal tech is complete without mentioning Antares Auto-Tune and Celemony Melodyne. These tools have defined the sound of the 21st century. While early versions struggled with the “thinness” of falsetto, modern iterations use ARA (Audio Random Access) technology to integrate deeply with Digital Audio Workstations (DAWs).
Melodyne allows for “Polyphonic Waveform Research,” which lets an editor reach inside a recorded audio file and grab a single falsetto note to change its vibrato, timing, or drift. This level of granular control means that the “falsetto” we hear on the radio is often a “cyborg” creation—part human biology, part advanced algorithmic correction.
Future Trends: Beyond the Human Range
As we look toward the future, the definition of falsetto continues to expand. Technology is pushing vocal expression into territories that were previously physically impossible for humans.
Voice Cloning and Ethical AI
Voice cloning technology (such as ElevenLabs or Meta’s Voicebox) can now generate falsetto tones from a few seconds of a person speaking in their normal chest voice. This has massive implications for digital security and synthetic media. If a machine can perfectly mimic a person’s falsetto—a register that is highly unique and difficult to fake—it raises questions about voice authentication and deepfakes.
From a tech trend perspective, the focus is shifting toward “zero-shot TTS” (Text-to-Speech), where an AI can read a script with the emotional fragility and airy quality of a falsetto performance without any human vocal input at all. This involves complex “Emotion Encoding,” where the software maps specific mathematical values to feelings like “vulnerability” or “intimacy,” which are hallmarks of the falsetto register.
The Integration of Synthetic Vocals in Digital Media
In the metaverse and high-end gaming, real-time vocal synthesis is becoming the standard. Imagine an AI-driven NPC (Non-Player Character) that can react to a player’s actions not just with words, but with a voice that cracks, whispers, or jumps into a falsetto of fear.
This requires “low-latency inference,” meaning the AI must calculate the vocal geometry in milliseconds. The hardware required to run these models—high-end GPUs and NPU (Neural Processing Unit) chips—is becoming more accessible, allowing “digital falsetto” to be a standard feature in interactive entertainment.
Conclusion: The Digital Resonance
What is falsetto voice in today’s tech-driven world? It is more than a vocal technique; it is a benchmark for the sophistication of digital audio. It is a complex set of frequencies that tests the limits of pitch-tracking algorithms, a data-rich challenge for neural networks, and a creative playground for software developers.
As AI continues to bridge the gap between biological output and digital synthesis, the falsetto remains one of the final frontiers of human “uniqueness” that technology is successfully decoding. Whether through the surgical precision of VSTs or the generative power of AI, the digital falsetto is a testament to our desire to replicate the most delicate aspects of our humanity through the lens of technology. For the modern tech enthusiast, understanding these mechanics is essential to navigating the future of sound, media, and digital identity.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.