In an era defined by the exponential growth of digital information, the challenge for modern enterprises is no longer just how to generate data, but how to store, manage, and protect it efficiently. As organizations scale their digital infrastructure, they inevitably encounter the “data bloat” phenomenon—a situation where storage systems become clogged with redundant copies of the same files, blocks, or segments. This is where “dedupe,” or data deduplication, becomes a critical component of the technological stack.
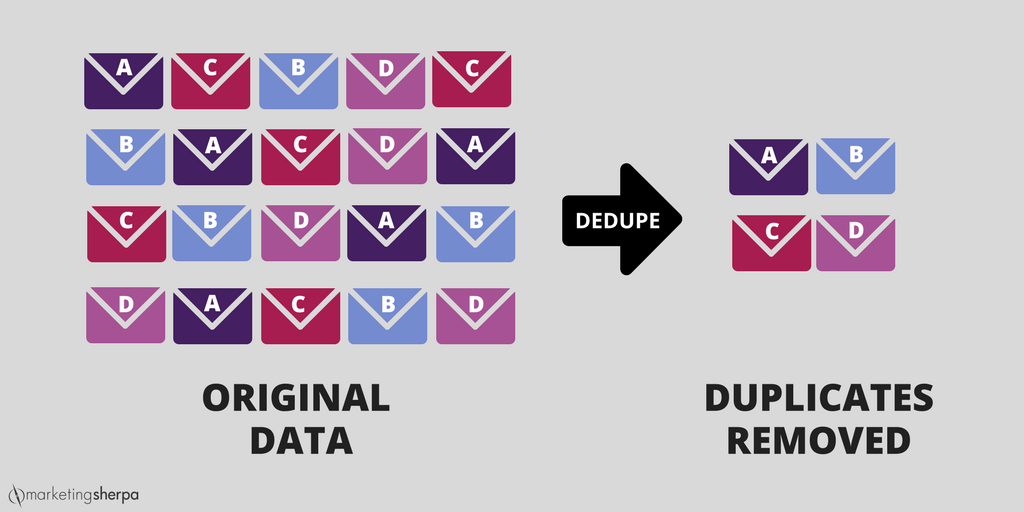
Data deduplication is a specialized data compression technique for eliminating duplicate copies of repeating data. In the simplest terms, it ensures that only one unique instance of data is actually retained on storage media, such as disk or tape. This process not only optimizes storage capacity but also enhances network performance and reduces the overall footprint of an organization’s digital assets. This article explores the mechanics, strategies, and technical implications of deduplication in today’s high-demand tech environments.
How Data Deduplication Works: The Mechanics of Efficiency
At its core, deduplication is about pattern recognition. When data is written to a system, the deduplication engine analyzes the incoming stream to identify segments that have already been stored. If the system recognizes a segment, the redundant copy is discarded, and a “pointer” is created that directs the user to the original, unique copy.
File-Level vs. Block-Level Deduplication
The granularity of deduplication determines its effectiveness. There are two primary levels at which this process occurs:
- File-Level Deduplication (Single-Instance Storage): This is the most basic form. It checks if an entire file is a duplicate of another file. For example, if ten employees save the same 10MB PDF attachment from an email to a shared server, file-level dedupe will store one 10MB file and nine pointers. However, if even one character is changed in one of those files, the system views it as an entirely new file and stores the whole thing again.
- Block-Level Deduplication: This is a much more granular and efficient approach. It breaks files down into smaller “blocks” or “chunks.” If a file is updated, only the changed blocks are saved as new data. The unchanged blocks are simply linked back to the existing versions. This is particularly effective for large databases or virtual machine images where small changes occur frequently within massive files.
The Role of Hash Functions
To identify unique data without comparing every bit manually—which would be computationally exhausting—deduplication systems use cryptographic hash functions like MD5, SHA-1, or SHA-256. When a block of data enters the system, the engine generates a “fingerprint” or hash for that block. If the hash matches an entry in the system’s index, the data is a duplicate. If the hash is unique, the data is stored, and the hash is added to the index for future reference.
Fixed-Length vs. Variable-Length Segmenting
In block-level deduplication, the system must decide how to “cut” the data. Fixed-length segmenting divides data into blocks of the same size (e.g., 8KB). While simple, it can be inefficient; if data is shifted slightly (like inserting a row in a spreadsheet), every subsequent block’s hash might change, breaking the dedupe process. Variable-length segmenting uses algorithms to look for natural breakpoints in the data, making the system much more resilient to shifts and significantly increasing the deduplication ratio.
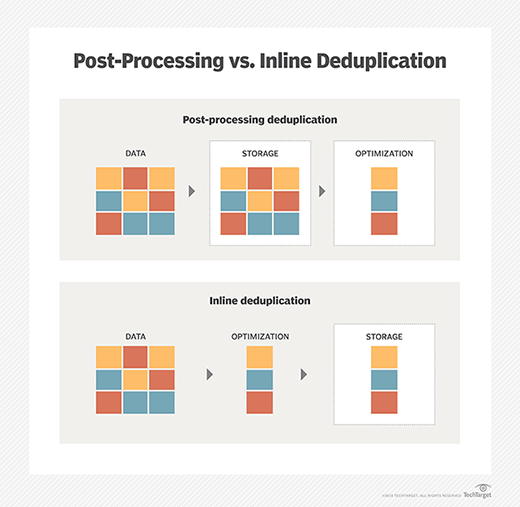
Strategic Implementation: Inline vs. Post-Process Dedupe
When a tech architect decides to implement deduplication, one of the most significant decisions involves when the deduplication occurs. This choice impacts system performance and storage hardware requirements.
Inline Deduplication
In an inline process, data is deduplicated in real-time as it is being written to the storage device. The dedupe engine sits between the data source and the storage media.
- Advantages: It minimizes the amount of storage space needed from the start because redundant data never hits the disk. This reduces the “wear and tear” on SSDs and lowers the total cost of storage hardware.
- Challenges: It requires significant processing power. If the dedupe engine cannot keep up with the incoming data stream, it creates a bottleneck, slowing down backup windows or application performance.
Post-Process Deduplication
Post-process deduplication allows data to be written to a temporary “landing zone” on the storage media in its native, raw format. Once the write operation is complete, or during a scheduled period of low activity, the system analyzes the data and removes duplicates.
- Advantages: There is no immediate impact on write performance. This is ideal for high-transaction environments where speed is the primary concern.
- Challenges: It requires more initial storage capacity to hold the “bloated” data before the deduplication process begins.

Source vs. Target Deduplication
Deduplication can also be categorized by where it happens in the network.
- Source Deduplication: The deduplication occurs at the client side (the server or workstation where the data originates) before it is sent over the network. This drastically reduces the amount of bandwidth required, making it perfect for remote offices or cloud backups.
- Target Deduplication: The data is sent in its entirety across the network, and the deduplication happens at the storage appliance or backup server. This offloads the processing burden from the production servers but requires a robust network to handle the initial data transfer.
The Technical Benefits of Dedupe in Modern Infrastructure
The implementation of deduplication technology is not merely a “nice-to-have” feature; it is a foundational necessity for managing modern tech ecosystems.
1. Storage Optimization and Physical Footprint Reduction
The most obvious benefit is the massive reduction in physical storage requirements. In typical enterprise backup environments, deduplication ratios can reach 10:1 or even 50:1. This means that 500TB of raw data might only occupy 10TB of physical disk space. For data centers, this translates to fewer racks, less power consumption, and reduced cooling requirements, contributing to a “greener” and more cost-effective IT operation.
2. Enhanced Disaster Recovery and Cloud Efficiency
In a disaster recovery (DR) scenario, data must be replicated to a secondary site or the cloud. Without deduplication, moving terabytes of data across a WAN (Wide Area Network) can take days or weeks. With deduplication—specifically source-side dedupe—only the unique, changed blocks are sent. This enables shorter Recovery Point Objectives (RPOs) and ensures that critical data is offsite and protected almost in real-time.
3. Virtualization and VDI Support
Virtual Desktop Infrastructure (VDI) is a classic use case for deduplication. In a VDI environment, hundreds of users may be running the same operating system (e.g., Windows 11). Without dedupe, the storage system would hold hundreds of identical copies of the OS files. Deduplication identifies these redundancies, allowing thousands of virtual desktops to run on a fraction of the storage typically required, while also improving boot times through cached unique blocks.
Navigating the Challenges: Performance and Data Integrity
While the benefits are substantial, deduplication introduces specific technical challenges that engineers must account for.
The “Deduplication Penalty” and Rehydration
When data needs to be read back or restored (a process known as rehydration), the system must reassemble the file from its various unique blocks and pointers. This can be slower than reading a contiguous, non-deduplicated file. For primary storage, where high-speed access is critical, developers must use high-performance flash storage and optimized metadata indexing to mitigate this “read penalty.”
Metadata Management and Fragmentation
Deduplication relies heavily on metadata (the index of hashes and pointers). If the metadata index becomes too large to fit in the system’s RAM, performance will plummet as the system begins “swapping” to disk. Furthermore, because deduplication scatters data blocks across different physical locations on a disk to maximize uniqueness, it can lead to heavy fragmentation. Modern storage operating systems counter this by using sophisticated layout algorithms that group related blocks together.
The Risk of Data Corruption
In a non-deduplicated system, if a sector on a disk fails, you lose one file. In a deduplicated system, if a unique block is corrupted, every file that points to that block is compromised. To counter this, enterprise-grade dedupe solutions implement rigorous data integrity checks, such as redundant storage of highly-referenced blocks and constant background “scrubbing” to detect and repair silent data corruption.
Conclusion: The Future of Deduplication and AI
As we look toward the future, deduplication technology is evolving beyond simple hash matching. We are seeing the rise of “intelligent” deduplication, where Machine Learning (ML) algorithms analyze data patterns to predict which data is likely to be redundant even before it is processed. Furthermore, as organizations move toward “multi-cloud” strategies, cross-cloud deduplication is becoming a priority, ensuring that data is not duplicated as it moves between providers like AWS, Azure, and Google Cloud.
Dedupe is more than just a storage-saving trick; it is a sophisticated data management philosophy. By understanding the nuances between block-level and file-level processing, and by strategically choosing between inline and post-process implementations, tech professionals can build resilient, scalable, and high-performance infrastructures that are ready for the data demands of tomorrow. In the world of Big Data, “dedupe” is the silent engine that keeps the digital world from drowning in its own redundancy.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.