In an increasingly data-driven world, the seemingly simple question of “what is the most common letter used in the alphabet?” transcends mere linguistic curiosity. For technology professionals, data scientists, and AI developers, understanding the frequency of letters in any given language corpus is not a trivial pursuit but a foundational building block for a myriad of advanced applications. From the earliest days of cryptography to the cutting edge of artificial intelligence and natural language processing (NLP), the statistical distribution of characters provides critical insights that power everything from efficient data compression to sophisticated predictive text algorithms. This article delves into the technological significance of letter frequency, exploring how this fundamental linguistic pattern underpins key innovations across the digital landscape. We’ll uncover the most common letters, examine the methodologies used to ascertain them, and, crucially, reveal why this seemingly elementary piece of information is indispensable for modern technological advancement.
The Foundational Science of Letter Frequency: A Deep Dive
The study of letter frequency, often referred to as frequency analysis, is a venerable field with roots stretching back centuries. Before the advent of computers, its primary application lay in the realm of code-breaking and linguistic analysis. Today, automated computational methods have transformed this process, enabling the analysis of vast text corpora—gigabytes, even terabytes, of written material—to derive highly accurate statistical models of character distribution.
Historical Context: From Cryptography to Early Computing
The concept of letter frequency gained prominence in the 9th century with the Arab polymath Al-Kindi, who devised methods for deciphering encrypted messages by analyzing the recurring patterns of letters. This technique, born from the need for secure communication, demonstrated a profound understanding that language is not random but structured, possessing inherent statistical properties. In later centuries, this principle became a cornerstone of intelligence and military strategy, famously employed to break ciphers like the German Enigma machine during World War II.
As the digital age dawned, the meticulous, manual process of counting letters gave way to algorithmic approaches. Early computer scientists recognized the power of automating such analyses, laying the groundwork for computational linguistics. The ability to quickly and accurately quantify letter occurrences opened doors to more efficient information processing and storage, paving the way for the development of modern text-based technologies.
Methodologies for Determining Frequency: Algorithmic Approaches
Determining letter frequency in a digital context involves sophisticated algorithms that process vast amounts of text. The core methodology is straightforward: iterate through a given text corpus, count each occurrence of every letter, and then calculate the proportion of each letter relative to the total number of letters. However, the nuances lie in the selection of the corpus, handling of case sensitivity, punctuation, and multi-word units.
Modern approaches leverage programming languages like Python with libraries such as NLTK (Natural Language Toolkit) or spaCy, which can tokenise text (break it into words or characters), normalise it (convert to lowercase, remove punctuation), and then apply frequency distribution functions. For truly massive datasets, distributed computing frameworks like Apache Hadoop or Spark are employed to process text in parallel, allowing for the analysis of entire digital libraries or web archives. These tools ensure that the derived frequencies are statistically robust and representative of the language as it is used in real-world contexts, rather than just small, biased samples.
The English Language Landscape: Unmasking the Usual Suspects
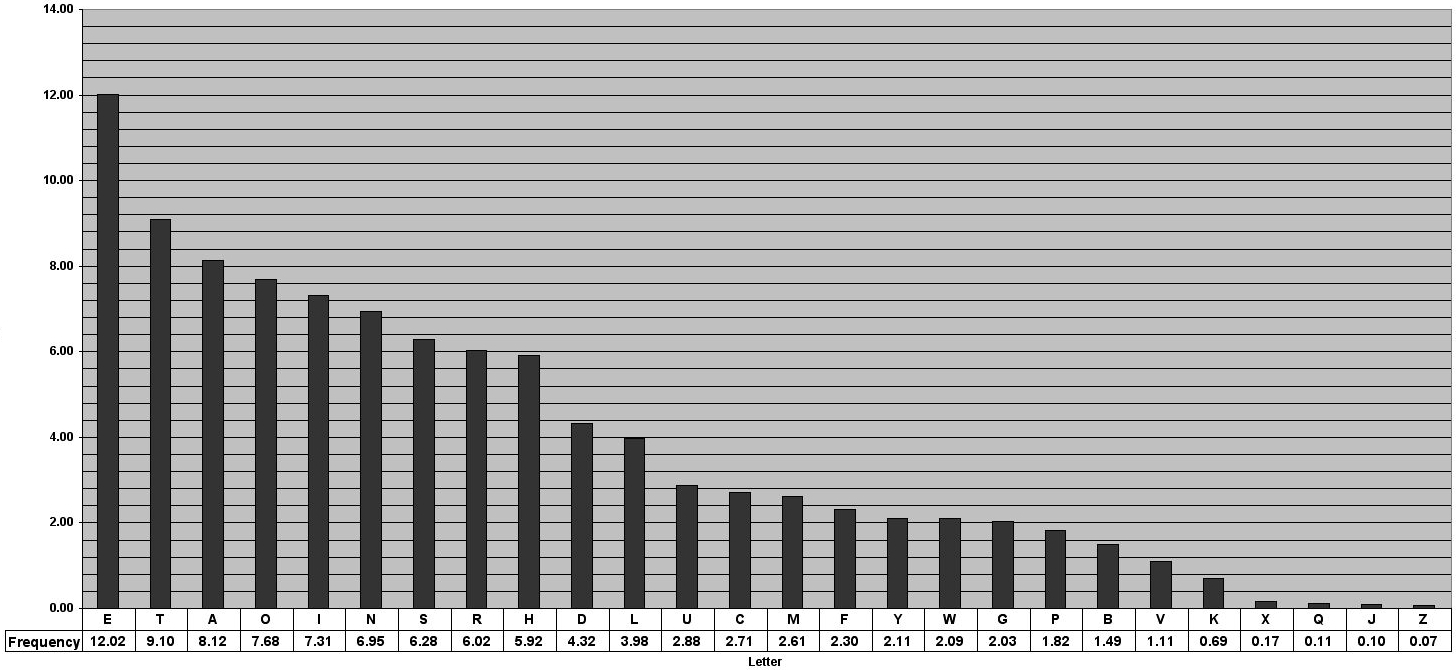
After countless analyses of diverse English text corpora—from literary works to web pages, news articles, and social media posts—a consistent pattern emerges. The most common letter in the English alphabet is, unequivocally, E. It typically accounts for around 11% to 12% of all letters. Following ‘E’, the letters ‘T’, ‘A’, ‘O’, ‘I’, ‘N’, ‘S’, ‘H’, and ‘R’ consistently rank high. Conversely, ‘Q’, ‘Z’, ‘J’, and ‘X’ are almost always found at the bottom of the frequency chart, appearing relatively rarely.
This statistical hierarchy is not just a fascinating tidbit; it’s a profound insight into the very structure and phonology of English. The prevalence of ‘E’ reflects its role in common short words (the, be, he), as a silent letter, and as part of frequent digraphs and trigraphs. This understanding forms the bedrock upon which many technological innovations are built, offering a predictive model of language that computers can exploit.
The Technological Imperative: Why Frequency Analysis Powers Modern Systems
The seemingly simple insight into letter frequency transforms into a powerful technological imperative when applied to complex systems. It’s a fundamental piece of data that informs the design and optimization of software, algorithms, and hardware, touching nearly every aspect of digital interaction.
Natural Language Processing (NLP) and AI Development
At the heart of modern artificial intelligence lies Natural Language Processing (NLP), a field dedicated to enabling computers to understand, interpret, and generate human language. Letter frequency, while a basic element, provides a crucial layer of insight for NLP models.
- Text Generation and Prediction Models: From autocomplete features on your smartphone to sophisticated AI writing assistants, language models like GPT (Generative Pre-trained Transformer) rely on statistical patterns to predict the next character or word. While these models operate at a much higher level (word and sentence embeddings), the foundational understanding of character distribution indirectly informs their training. Knowing that ‘e’ is common helps to refine probabilistic outcomes for letter sequences, ensuring more natural-sounding outputs.
- Sentiment Analysis and Information Extraction: Although sentiment analysis primarily focuses on words and phrases, the underlying efficiency of processing vast texts is enhanced by knowing letter frequencies. Text processing pipelines, which are the first step in preparing data for sentiment analysis or entity extraction, can be optimized for character distribution. Moreover, in less structured text, unusual character frequencies might even flag potential errors or non-standard language.
Data Compression and Efficiency in Storage/Transmission
One of the earliest and most impactful applications of letter frequency analysis in computing was in data compression. The goal of compression algorithms is to reduce the size of data without losing essential information, making storage more efficient and transmission faster.
- Huffman Coding: A classic example is Huffman coding, an algorithm that assigns shorter binary codes to more frequent characters and longer codes to less frequent ones. Because ‘E’ appears so often, assigning it a very short code (e.g., ‘0’ or ’00’) significantly reduces the overall bit length of a text file. Conversely, ‘Z’ might get a much longer code. This method, rooted directly in frequency analysis, is a cornerstone of various file formats and network protocols, demonstrating how a simple linguistic observation translates into tangible performance gains in data handling.
Cryptography and Digital Security: A Historical and Modern Perspective
While modern cryptography has moved far beyond simple substitution ciphers, the principles of frequency analysis remain a fundamental concept in understanding and even designing secure systems.
- Breaking Early Ciphers: As mentioned, frequency analysis was the primary tool for breaking classical substitution ciphers. If ‘E’ is the most common letter in English, then the most common encrypted character in a simple substitution cipher likely corresponds to ‘E’. This vulnerability pushed cryptographers to develop more complex polyalphabetic ciphers, which obscure frequency patterns.
- Modern Cryptanalysis Education: Even today, teaching classical cryptanalysis techniques, including frequency analysis, is crucial for aspiring cybersecurity professionals. It helps them understand the fundamental principles of cryptographic strength and weakness, emphasizing the importance of randomness and diffusion in contemporary encryption algorithms. It serves as a stark reminder that inherent patterns in data can be exploited if not adequately protected.
User Interface and Experience (UI/UX) Design: Keyboard Layouts and Input Prediction
The physical and digital interfaces we use daily are subtly influenced by letter frequency to enhance usability and speed.
- Keyboard Layouts (e.g., QWERTY): The QWERTY keyboard layout, though often criticized for its inefficiency, was originally designed to slow down typists to prevent mechanical typewriter jams. However, subsequent layouts like Dvorak were explicitly designed to optimize typing speed by placing the most common letters on the home row, where fingers rest naturally. This directly leverages frequency analysis to minimize finger travel and improve ergonomic efficiency. While QWERTY remains dominant, the principle of frequency-based optimization is evident in alternative designs and informs ergonomic considerations.
- Predictive Text and Autocorrect: The predictive text features on smartphones and virtual keyboards heavily rely on sophisticated language models trained on vast corpora. While these models go beyond single-letter frequency, the underlying statistical probabilities of character sequences are influenced by how often certain letters appear together or begin/end words. Autocorrect algorithms also factor in common letter patterns to suggest the most probable corrections for typos.
The Toolkit: Leveraging Programming and AI for Linguistic Insights
Performing frequency analysis and applying its insights requires a robust set of technological tools and platforms. From general-purpose programming languages to specialized AI services, the modern tech stack empowers developers and researchers to unlock the patterns hidden within vast amounts of text.
Programming Languages and Libraries: Python, R, and Their Ecosystems
Python is arguably the most popular language for text analysis and NLP due to its readability and a rich ecosystem of libraries.
- NLTK (Natural Language Toolkit): A comprehensive library for linguistic analysis, NLTK provides functionalities for tokenization, stemming, lemmatization, and, of course, frequency distribution. It’s a staple for academic research and educational purposes.
- spaCy: Designed for production use, spaCy offers highly optimized and efficient components for various NLP tasks, including named entity recognition, part-of-speech tagging, and dependency parsing. While it doesn’t have a direct “frequency counter” as a core feature, its text processing capabilities are essential for preparing data for such analyses.
- TextBlob: Built on top of NLTK, TextBlob provides a simpler API for common NLP tasks, making it accessible for quick scripting and prototyping, including basic frequency counting.
R, a language favored by statisticians and data analysts, also offers powerful text mining packages like tm and quanteda, which are well-suited for corpus analysis and frequency determination, often integrated with statistical modeling.
Big Data Analytics Platforms for Text Corpora
When dealing with datasets that are too large for a single machine, big data platforms become indispensable.
- Apache Hadoop and Spark: These distributed computing frameworks enable the processing of petabytes of text data across clusters of machines. MapReduce paradigms are particularly well-suited for tasks like counting occurrences of items (in this case, letters) across massive documents, efficiently aggregating results from thousands of files.
- Elasticsearch: A distributed search and analytics engine, Elasticsearch can index and analyze vast quantities of text data in near real-time. It provides powerful querying capabilities that can be used to extract frequency statistics, making it a valuable tool for dynamic linguistic analysis in applications like search engines or log analysis.
Cloud-Based NLP Services: AWS Comprehend, Google Cloud NLP, Azure Cognitive Services
For developers who need to integrate sophisticated NLP capabilities without building models from scratch, cloud providers offer powerful APIs.
- AWS Comprehend: Amazon’s NLP service can analyze text for key phrases, sentiment, entities, and language. While it doesn’t directly give a letter frequency API, its underlying models are built upon foundational linguistic statistics, and it can be used to process texts that are then fed into custom frequency analysis tools.
- Google Cloud Natural Language API: Similar to AWS Comprehend, Google’s service provides advanced text analysis capabilities. Its strength lies in its deep learning models that handle complex linguistic nuances, all of which implicitly rely on understanding character and word distributions.
- Azure Cognitive Services (Text Analytics): Microsoft’s offering provides APIs for sentiment analysis, key phrase extraction, and language detection. These services abstract away the complexity of building and training large NLP models, allowing developers to focus on application logic, knowing that the underlying technology is robustly informed by linguistic patterns like letter frequency.
The Frontier: Multilingualism, Ethical AI, and the Future of Text Understanding
As technology continues its relentless march forward, the simple concept of letter frequency remains relevant, evolving alongside more complex challenges like multilingualism and the ethical considerations of AI.
Cross-Lingual Frequency Variations and Their Implications
The frequency of letters is highly language-dependent. While ‘E’ dominates English, ‘A’ is often more common in Spanish and French, and ‘O’ or ‘I’ might lead in others. This variation has significant implications for cross-lingual NLP and AI:
- Machine Translation: Understanding these differences is crucial for developing accurate machine translation models. A system that accounts for the typical letter and phonetic structures of the target language will produce more natural and contextually appropriate translations.
- Language Identification: Basic frequency analysis can be a preliminary step in identifying the language of a given text, a critical function in global software applications, content moderation, and international communications.
AI’s Advanced Understanding of Language Structure
Modern AI models, particularly large language models (LLMs), have moved beyond simple letter frequencies to grasp incredibly complex patterns in language. They don’t just count letters; they learn the semantic, syntactic, and contextual relationships between words, phrases, and even entire documents. However, these advanced capabilities are built upon a hierarchy of linguistic understanding, where foundational statistical patterns like letter frequency provide the very first layer of data for the neural networks to process and learn from. The sheer volume of text data they are trained on allows them to derive these patterns implicitly, leading to unprecedented levels of language generation and comprehension.

Ethical Considerations and Bias in Text Data Analysis
The choice of text corpus for frequency analysis, or any linguistic analysis, carries significant ethical implications. If the training data for an AI model is biased—e.g., predominantly male-authored texts, specific dialects, or texts from certain demographics—the resulting model will perpetuate and amplify those biases.
- Algorithmic Fairness: Understanding letter and word frequencies across diverse linguistic groups is essential for ensuring algorithmic fairness. For instance, if an AI text generator is trained primarily on data where certain demographic names are rare, it might misspell them or treat them as errors.
- Representation: Developers must actively curate diverse and representative datasets to avoid building AI systems that are less effective or even discriminatory towards certain linguistic or cultural groups. The foundational insights from letter frequency analysis, when performed on a truly diverse global corpus, can highlight areas where data collection needs to improve to ensure equitable technological advancement.
In conclusion, the answer to “what is the most common letter used in the alphabet?”—which is ‘E’ for English—is far more than a simple factoid. It is a gateway to understanding the profound statistical underpinnings of human language, a principle that has been harnessed by technology for centuries. From cracking ancient codes to compressing digital files, optimizing keyboards, and powering the sophisticated AI that defines our modern digital experience, letter frequency analysis remains a vital, albeit often unseen, force in the technological world. As we push the boundaries of AI and engage with an increasingly multilingual and interconnected global society, this foundational insight will continue to evolve, shaping the future of how humans and machines interact with language.