In the rapidly evolving landscape of technology, innovation is constant, but true progress hinges on robust validation. Every new feature, algorithm, or user interface design represents a hypothesis: will this improve performance, enhance user engagement, or solve a critical problem more effectively? Answering these questions with confidence requires more than just intuition or anecdotal evidence; it demands rigorous, scientific methodology. This is where the Randomized Controlled Trial (RCT) — a gold standard in scientific research — steps into the tech arena.
Traditionally revered in medical research for its ability to establish cause-and-effect relationships, the RCT is increasingly becoming an indispensable tool for tech companies. From refining complex AI models to optimizing the minutiae of user experience, RCTs provide a powerful framework for data-driven decision-making, ensuring that technological advancements are not just novel, but genuinely effective. This article delves into the core principles of RCTs and explores their profound significance and application within the dynamic world of technology.
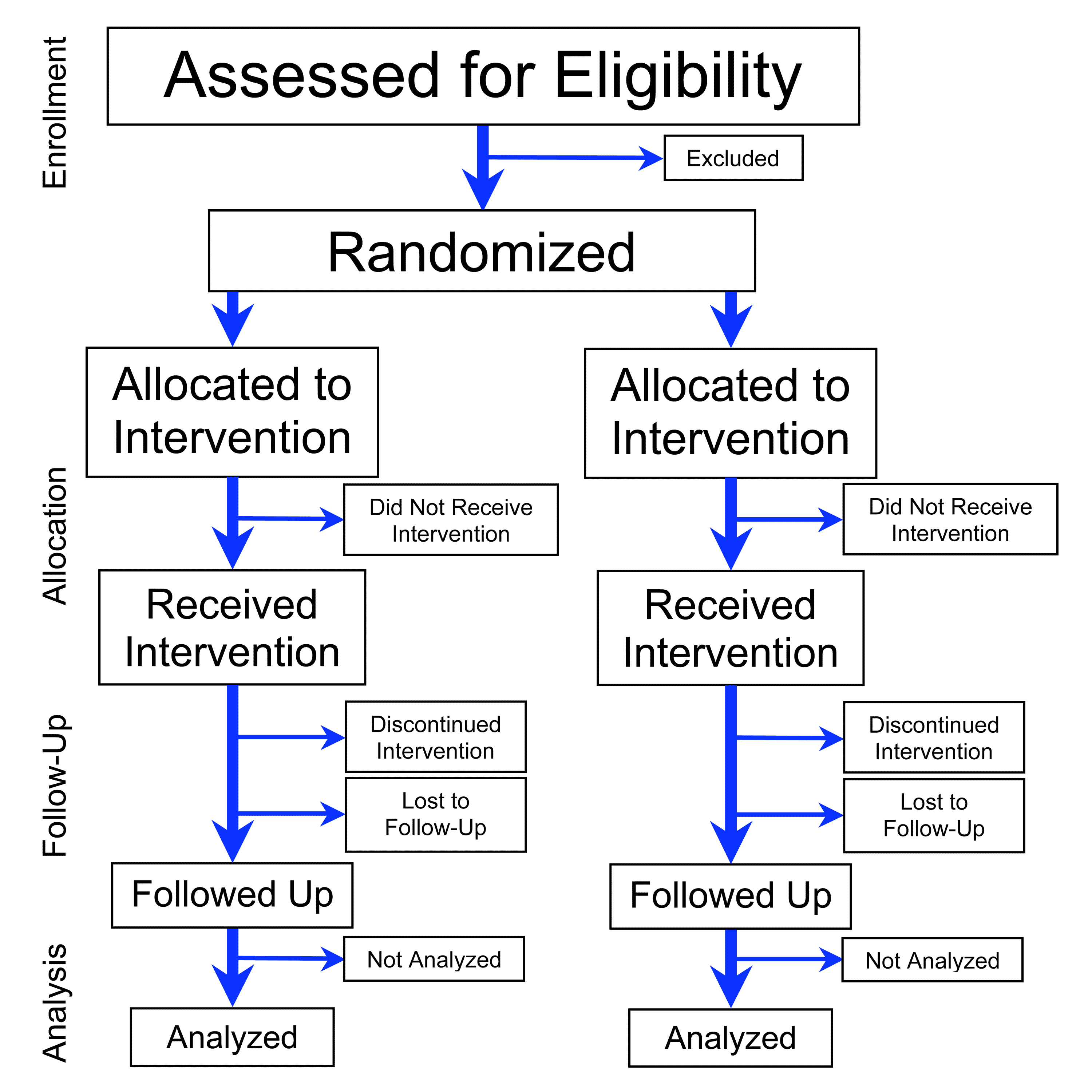
The Core Mechanics of Randomized Controlled Trials
At its heart, an RCT is an experimental design aimed at minimizing bias and maximizing the validity of findings when comparing two or more interventions. While the context might shift from a new drug to a redesigned website button, the underlying logic remains steadfast.
Randomization: The Cornerstone of Unbiased Results
The defining feature of an RCT is randomization. Participants (whether human users, data packets, or server requests) are randomly assigned to one of at least two groups: an intervention group or a control group. This random assignment is critical because it ensures that, on average, all other factors that might influence the outcome are evenly distributed between the groups.
Imagine a tech company testing two different versions of an onboarding flow for a new app. Without randomization, if users who signed up through a specific marketing campaign (e.g., tech-savvy early adopters) were predominantly directed to one version, it would be impossible to tell if any observed difference in completion rates was due to the onboarding flow itself or to the inherent characteristics of that user group. Randomization neutralizes these confounding variables, isolating the effect of the intervention being tested. It’s like shuffling a deck of cards thoroughly before dealing them; each card has an equal chance of landing in any hand, minimizing pre-existing biases.
Control Groups vs. Intervention Groups
Every RCT requires a basis for comparison. This comes in the form of at least two distinct groups:
- Intervention Group(s): These are the participants who receive the specific feature, algorithm update, UI change, or new process being tested. In tech, this could be users exposed to a new search algorithm, an updated checkout process, or a redesigned dashboard. There can be multiple intervention groups if several variations are being tested simultaneously.
- Control Group: This group serves as the baseline. They either receive the standard, existing version (e.g., the current app design, the old algorithm) or sometimes a placebo (though less common in pure tech contexts, it conceptually aligns with providing a “no-change” experience). The control group allows researchers to measure the incremental impact of the intervention by comparing its outcomes against a group that did not receive it. Without a control, it’s impossible to know if observed changes are due to the intervention or other external factors, such as general market trends or seasonal variations.
Blinding: Mitigating Bias in Data Collection
While randomization addresses selection bias, blinding (or masking) aims to prevent performance and detection bias. In medical trials, this means patients don’t know if they’re getting the drug or a placebo (single-blind), and sometimes even the researchers administering treatment don’t know (double-blind).
In tech, blinding can be more nuanced but still relevant:
- Single-blind: If a user is unaware they are part of an experiment and doesn’t know which version of a feature they are using, this is akin to single-blinding. This helps ensure their behavior is natural and not influenced by their awareness of being in a test.
- Double-blind: This is harder to achieve in tech but conceptually means that the analysts evaluating the data are also unaware of which group received which intervention until after the analysis is complete. This prevents subconscious biases from influencing data interpretation, especially when qualitative data or subjective assessments are involved. While often not feasible for product developers themselves, independent data auditors or automated analysis pipelines can serve a similar function.
Why RCTs are Indispensable in Tech Development
The principles of RCTs, particularly the rigorous A/B testing methodology they inspire, have become critical for tech companies seeking to build truly effective products and services.
Validating Software Features and User Experience (UX)
Every new software feature, button placement, color scheme, or navigational change is a hypothesis about user behavior. Will this new button increase conversions? Will this simplified workflow reduce user frustration? RCTs, in the form of A/B tests or multivariate tests, provide the definitive answer.
By randomly assigning users to experience either the existing design (control) or a new design (intervention), companies can objectively measure key metrics like click-through rates, conversion rates, time on page, task completion rates, or error rates. This evidence-based approach prevents costly redesigns based on conjecture and ensures that UX improvements are genuinely impactful, leading to more intuitive and effective software. It also allows product teams to iterate rapidly, testing multiple hypotheses simultaneously and quickly discarding those that don’t perform.
Evaluating AI Algorithms and Machine Learning Models
The development of Artificial Intelligence and Machine Learning models involves continuous refinement. A new algorithm might promise faster processing, higher accuracy, or more relevant recommendations. But how do you prove its superiority over the existing model?
RCTs offer a robust framework. For instance, an e-commerce platform could randomly assign users to an old recommendation algorithm (control) or a new, AI-powered one (intervention). Metrics such as purchase frequency, basket size, or product discovery rates could then be compared. Similarly, for AI in content moderation, an RCT could compare the false positive/negative rates of a human team (control) against an AI-assisted team (intervention) or two different AI models. This methodical evaluation is crucial for ensuring that AI integrations truly deliver on their promise and do not introduce unintended biases or detrimental user experiences.
Data-Driven Decision Making and Product Iteration
In the tech industry, data is king. However, raw data without context or rigorous testing can be misleading. RCTs provide the scientific rigor to transform data into actionable insights. Instead of making decisions based on opinion, correlation, or limited observation, companies can leverage RCT results to justify significant investments, prioritize development efforts, and refine product roadmaps.
This commitment to experimentation fosters a culture of continuous learning and iteration. Teams can quickly identify what works and what doesn’t, allowing them to fail fast, learn faster, and adapt their strategies based on irrefutable evidence. This iterative cycle, powered by RCTs, is fundamental to staying competitive and delivering user value in a rapidly changing technological landscape.
Designing and Implementing RCTs in a Tech Environment
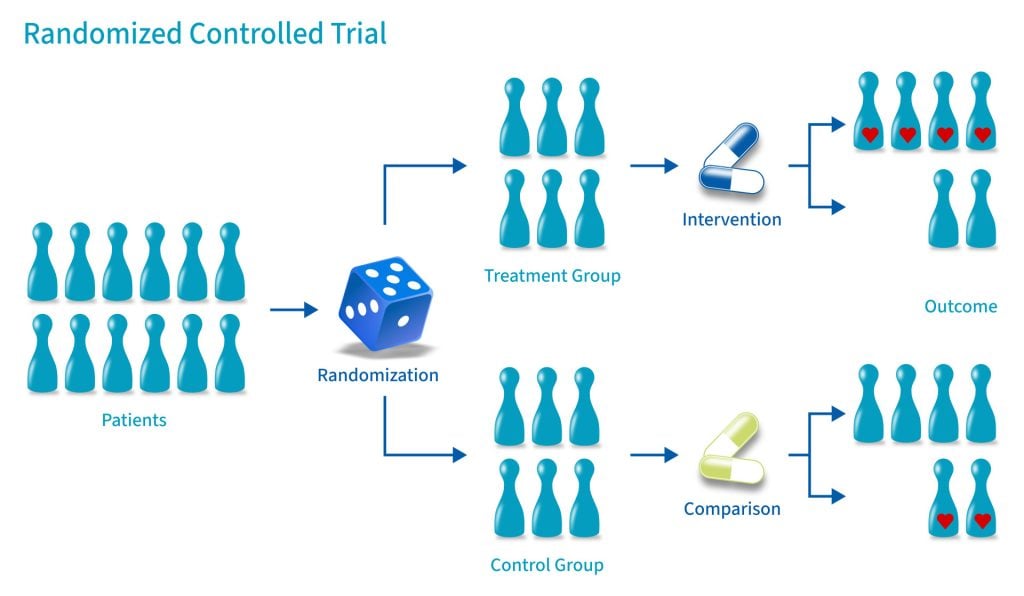
While the theoretical underpinnings of RCTs are consistent, their practical application in a tech context requires specific considerations and tools.
Defining Clear Hypotheses and Metrics
Before launching any experiment, clarity is paramount. A well-defined hypothesis is essential – a testable statement predicting the outcome of the intervention. For example: “Implementing a single-page checkout process (intervention) will increase conversion rates by 5% compared to the multi-page checkout (control) for mobile users.”
Alongside the hypothesis, explicit metrics must be identified and tracked. These are the quantifiable measures that will determine success or failure. They can include:
- Conversion rates: Purchases, sign-ups, downloads.
- Engagement metrics: Time on site, clicks, active sessions.
- Performance metrics: Page load times, error rates.
- Retention metrics: Churn rate, repeat visits.
Defining these upfront ensures that data collection is focused and that the experiment has clear success criteria.
Tools and Platforms for A/B Testing and Experimentation
The tech industry has developed a sophisticated ecosystem of tools specifically designed to facilitate RCTs, often referred to as A/B testing or experimentation platforms. These tools automate much of the complex work involved in running digital experiments:
- User assignment: Randomly allocating users to different groups.
- Variant delivery: Showing the correct version of a feature to each group.
- Data collection: Tracking relevant metrics for each group.
- Statistical analysis: Providing tools to determine if observed differences are statistically significant.
Popular platforms include Optimizely, VWO, Google Optimize (though phasing out, its concepts remain relevant), and numerous in-house solutions developed by large tech companies. These platforms abstract away the technical complexity, allowing product managers, designers, and marketers to run experiments efficiently.
Ethical Considerations in Digital Experimentation
Running experiments on real users, even within a digital environment, carries ethical responsibilities. Companies must consider:
- User consent: While explicit consent for minor UI changes might be impractical, transparency about data usage and the right to privacy are critical. Major behavioral experiments might require more explicit opt-in.
- Minimizing harm: Experiments should not intentionally degrade user experience or expose users to significant risks. The potential benefits of the experiment should outweigh any potential negative impact.
- Data privacy and security: All data collected during experiments must adhere to strict privacy regulations (e.g., GDPR, CCPA) and robust security protocols.
- Bias in participant selection: While randomization helps, care must be taken to ensure that experiments are not inadvertently excluding or unfairly targeting certain user demographics.
Ethical guidelines and internal review processes are crucial to ensure that experiments are conducted responsibly and maintain user trust.
Challenges and Nuances of RCTs in Tech
While powerful, RCTs in tech are not without their complexities and challenges. Understanding these nuances is key to effective implementation.
Scalability and Sample Size Requirements
For an RCT to yield statistically significant results, it often requires a sufficiently large sample size. In tech, this means enough users participating in the experiment to detect meaningful differences between groups. For products with millions of users, this might be relatively easy. For niche products or features with limited reach, achieving the necessary sample size can be a significant hurdle, prolonging experiment duration or making it difficult to detect subtle effects.
Furthermore, running multiple simultaneous RCTs can strain infrastructure and introduce “interference effects” where one experiment unintentionally impacts another. Managing and orchestrating these experiments at scale requires sophisticated experimentation platforms and robust data infrastructure.
The Dynamic Nature of Tech Environments
Unlike a controlled laboratory setting, the tech environment is constantly in flux. Software updates, external market changes, viral trends, and even competitor actions can all influence user behavior during an ongoing RCT. These external factors can introduce noise, making it harder to attribute changes solely to the intervention being tested.
Therefore, tech RCTs often need to be relatively short-lived or incorporate sophisticated analytical methods to account for seasonality, trends, and other confounding variables that might emerge during the experiment’s duration. Continuous monitoring and A/A tests (testing two identical versions against each other to establish a baseline of noise) can help in understanding the inherent variability.
When to Opt for Alternatives (and when not to)
While RCTs are the gold standard for establishing causality, they are not always feasible or necessary.
-
When to consider alternatives:
- Pilot studies/Qualitative research: For early-stage ideas or fundamental design changes, qualitative research (user interviews, usability testing) can provide rich insights and guide initial design, informing hypotheses for later RCTs.
- Observational studies/Correlation: To identify potential areas for improvement or discover interesting patterns, observational data analysis can reveal correlations. However, these cannot prove causation and should ideally be followed by an RCT if a causal link needs to be established.
- Cost/Ethical constraints: Some interventions might be too costly or ethically challenging to implement as a full RCT.
- Small sample sizes: When the user base is too small for statistical significance, other methods might be more practical.
-
When not to compromise on RCTs:
- High-impact changes: For features that significantly alter core user flows, revenue, or security, the rigor of an RCT is invaluable.
- Ambiguous results from other methods: If qualitative insights are conflicting or observational data presents multiple plausible explanations, an RCT can provide clarity.
- Optimization of critical metrics: When fine-tuning performance, conversion, or engagement metrics that directly impact business outcomes, RCTs are essential for robust decision-making.
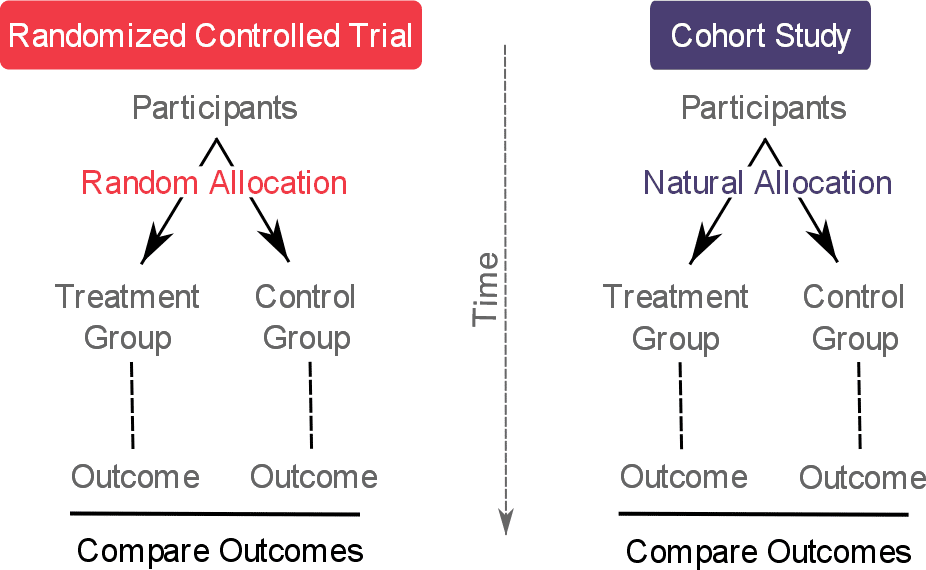
Conclusion
The Randomized Controlled Trial, once primarily a medical domain staple, has firmly cemented its place within the tech industry. As technology becomes increasingly integrated into every facet of our lives, the imperative to build products that are not just innovative but also genuinely effective, user-centric, and ethically sound grows stronger. By applying the scientific rigor of randomization, control groups, and systematic measurement, tech companies can move beyond guesswork and subjective opinions, making truly data-driven decisions that lead to superior software, smarter AI, and ultimately, a better user experience. In a world defined by rapid change, the RCT provides a timeless framework for proving what truly works, ensuring that technological progress is built on a foundation of solid evidence.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.